La prévision de la demande future constitue la base de toutes les décisions stratégiques et de planification dans une chaîne d'approvisionnement. Une entreprise définit ses efforts en fonction de l’orientation de son activité, qui peut être déterminée en l’appuyant sur une méthode appropriée de prévision de la demande. De plus, celle ci est à la base d'un processus de planification industrielle et commerciale (PIC) couvrant la production, les ventes, le marketing et les domaines de la finance, pour permettre aux gestionnaires de diriger correctement et aligner leurs actions sur des données plutôt que fondées sur des hypothèses individuelles.

Essayez notre solution de prévision simple & rapide !
Inscrivez-vous aujourd’hui gratuitement sur SKU Science
Données d’échantillon préchargées – Aucune carte de crédit requise
Pour réussir à suivre cette approche et garantir des résultats fiables, les responsables doivent prendre des décisions importantes concernant les prévisions et le type de technique de prévision de la demande. Différentes techniques sont disponibles, mais avec des différences substantielles entre elles qu'il convient de choisir en tenant compte de plusieurs facteurs. La plupart des techniques étant quantitatives , ces facteurs doivent inclure le niveau de complexité des produits ou du marché, la maturité des processus de la chaîne d'approvisionnement de l'entreprise et la disponibilité de données fiables.
Plusieurs techniques de prévision de la demande de base bien connues, pouvant servir de point de départ, utilisent des données historiques pour prédire l'avenir, mais avec quelques différences qui seront expliquées ci-dessous et dans les articles suivants.
Le modèle de prévision de la moyenne mobile
Le premier et le plus élémentaire est le modèle de moyenne mobile, une méthode de prévision de la demande basée sur l’idée que la demande future est similaire à la demande récente observée. Dans ce modèle, on suppose simplement que la prévision est la moyenne de la demande au cours des n dernières périodes. Si vous regardez la demande sur une base mensuelle, cela pourrait se traduire par «Nous prévoyons que la demande en juin sera la moyenne de mars, avril et mai».
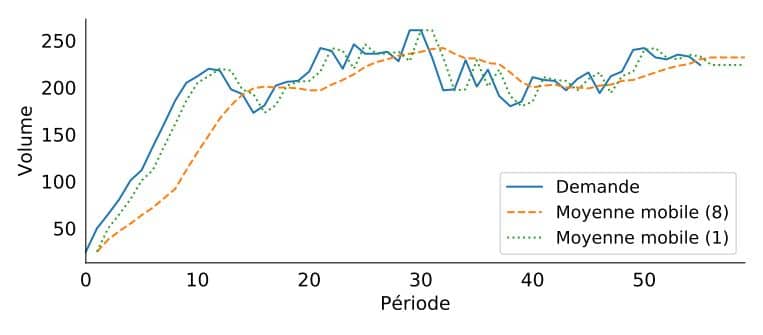
L'une des conditions de base du modèle est de commencer à créer une base de données historique, car vous ne disposerez pas de prévisions avant que suffisamment d'observations de la demande aient été collectées. Une fois sorti de la période historique, vous définissez simplement les prévisions futures comme les dernières faites sur la base de la demande historique. Cela signifie qu'avec ce modèle, la prévision de la demande future sera stable. Par conséquent, l'une des principales restrictions de ce modèle sera son incapacité à extrapoler les tendances.
Modèle de prévision de la demande de lissage exponentiel
En ce qui concerne la moyenne mobile, on suppose que l'avenir sera plus ou moins le même que le passé. De même, le modèle de lissage exponentiel sera capable d'apprendre le niveau à partir de l'historique de la demande. Le niveau est la valeur moyenne autour de laquelle la demande varie dans le temps. Il est important de comprendre qu’il n’existe pas de définition mathématique définitive du niveau; à la place, il appartient à notre modèle de l’estimer.
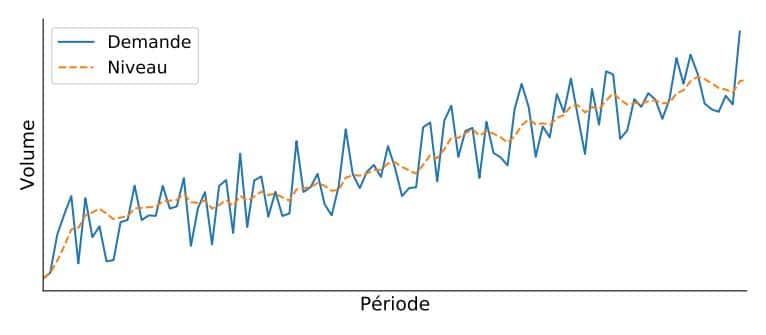
Comme vous pouvez le constater, le modèle de lissage exponentiel prévoira ensuite les demandes futures en tant que dernière estimation du niveau.
L'idée de base de tout modèle de lissage exponentiel est que, à chaque période, le modèle apprendra un peu à partir de l'observation de la demande la plus récente et se rappellera un peu de la dernière prévision établie. La magie à ce sujet est que la dernière prévision du modèle comprend une partie de l’observation de la demande précédente et une partie de la prévision précédente. Et ainsi de suite. Par conséquent, cette prévision précédente inclut en réalité tout ce que le modèle a appris jusqu'à présent, en fonction de l'historique de la demande.
Le paramètre de lissage (ou taux d'apprentissage) alpha ( ) déterminera quelle importance est accordée à l'observation de la demande la plus récente. Représentons ceci mathématiquement:
) déterminera quelle importance est accordée à l'observation de la demande la plus récente. Représentons ceci mathématiquement:
![\[f_t=\alpha d_{t-1}+(1-\alpha) f_{t-1}\]](https://www.skuscience.com/wp-content/ql-cache/quicklatex.com-3909be3b838debbd575aaac2ae53df0b_l3.png "Rendered by QuickLaTeX.com")
![\[0 < \alpha \leq 1\]](https://www.skuscience.com/wp-content/ql-cache/quicklatex.com-9c83ebcb465a9c56d953a9a7d73442ab_l3.png "Rendered by QuickLaTeX.com")
 représente l'observation de la demande précédente multipliée par le taux d'apprentissage.
représente l'observation de la demande précédente multipliée par le taux d'apprentissage.
 représente la manière dont le modèle se souvient de sa prévision précédente.
représente la manière dont le modèle se souvient de sa prévision précédente.
Sur la figure ci-dessous, nous voyons qu’une prévision faite avec une valeur alpha basse (ici 0,1) mettra plus de temps à réagir à une demande changeante, tandis qu’une prévision ayant une valeur alpha élevée (ici 0,8) suivra de près les fluctuations de la demande. Vous pouvez trouver plus d'informations sur ce modèle sur supchains.com
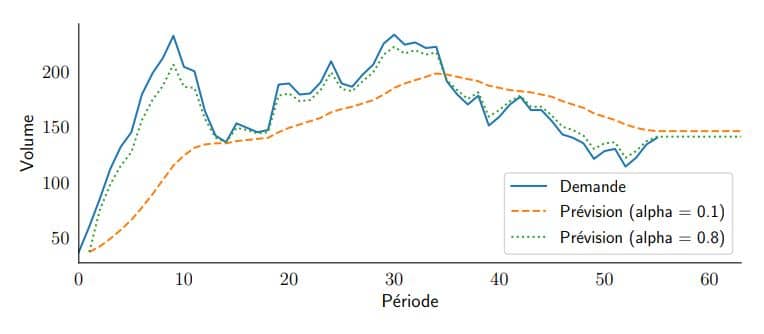
Un modèle de prévision de la demande avantageux et un point de départ important
Il convient de souligner deux avantages clés sur le lissage exponentiel:
• Le poids associé à chaque observation diminue de manière exponentielle avec le temps (l'observation la plus récente a le poids le plus élevé).
• Nous pouvons réduire l'impact des valeurs aberrantes et du bruit grâce à alpha (α), le poids exponentiel.
Comme expliqué dans le livre “Data Science for Supply Chain Forecast” écrit par Nicolas Vandeput, un compromis important doit être fait entre apprendre et se souvenir; entre être réactif et être stable. Si le taux d'apprentissage est élevé, le modèle accordera une plus grande importance à l'observation de la demande la plus récente et sera réactif à une modification du niveau de la demande. Mais il sera également sensible aux valeurs aberrantes et au bruit. D'autre part, si le taux d'apprentissage est faible, le modèle ne remarquera pas de changement de niveau rapidement, mais ne réagira pas de manière excessive avec le bruit et les valeurs aberrantes.
Mais il faut aussi prendre en compte certaines contraintes de planification de la demande:
• Le modèle de lissage exponentiel ne projette pas de tendances et ne reconnaît aucun schéma saisonnier.
• Il ne peut utiliser aucune information externe (telle que les prix ou les frais de marketing).
Réflexions finales sur le choix d'une méthode de prévision de la demande pour améliorer la gestion des stocks
Ce premier modèle de lissage exponentiel sera probablement trop simple pour obtenir de bons résultats, mais il constitue une bonne base pour la création ultérieure de modèles plus complexes. Pour éviter certaines des lacunes décrites ici, il existe des techniques de lissage plus avancées décrites dans un autre article de blog . De plus, vous pouvez voir ces modèles appliqués à vos données dans SKU Science afin de les comparer et laisser notre algorithme choisir le meilleur pour chaque prévision.