
La plupart des chaînes d’approvisionnement s’attendent à une certaine variabilité de la demande et, par conséquent, il convient de choisir le bon modèle de prévision, comme on peut le voir dans nos précédents articles. Quelle que soit la nature de cette variance, des facteurs exceptionnels peuvent se produire et nuire gravement à la fiabilité d’un modèle donné. Nous appelons ces données des « valeurs aberrantes ».
Ces valeurs aberrantes résultent d’abord d’une demande exceptionnelle, telle que la liquidation de stocks, des arrêts temporaires de production ou des restrictions externes, qui peuvent être dues à des contraintes logistiques ou d’infrastructures rendant temporairement impossible la composition du stock ou l’exécution des commandes des clients. Même si certaines observations de la demande sont réelles, cela ne signifie pas qu’elles ne sont pas exceptionnelles et ne doivent pas être nettoyées.
Deuxièmement, il y a aussi des erreurs, qui sont des valeurs aberrantes évidentes. Si vous remarquez ce type d’erreurs ou des problèmes d’encodage, vous devez mettre en œuvre des améliorations de processus afin d’empêcher qu’elles ne se reproduisent.
Considérant les effets négatifs que les valeurs aberrantes peuvent avoir sur votre entreprise, il est essentiel de savoir comment les détecter et il existe certaines techniques qui peuvent être utilisées pour résoudre ce problème.
Essayez notre solution de prévision simple et rapide !
Inscrivez-vous aujourd’hui gratuitement sur SKU Science
Données d’échantillon rechargées – Aucune carte de crédit requise
Détecter les valeurs aberrantes via la winsorization
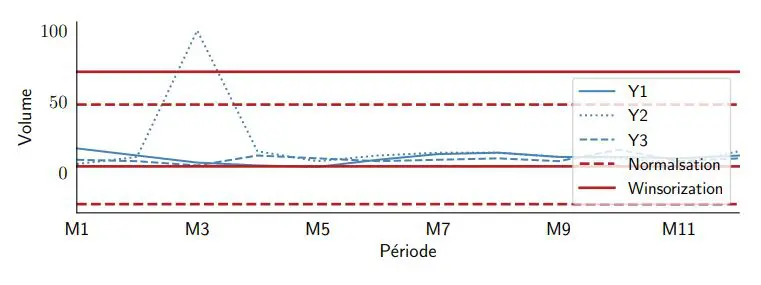
Cette première idée est une approche plutôt simpliste consistant à définir une certaine plage minimale et maximale dans laquelle les données seront simplement ignorées. Statistiquement, cette marge est définie comme le centile, ce qui signifie la valeur en dessous de laquelle x% des observations dans un groupe vont tomber. Par exemple, 99% des observations de la demande pour un produit seront inférieures à son 99e centile.
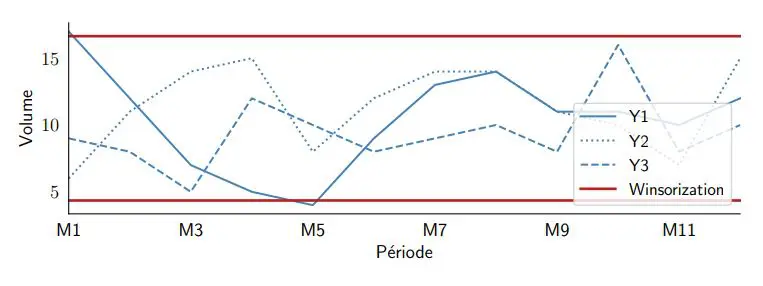
Cette approche peut être efficace, mais elle peut également entraîner certains problèmes, tels que la détection de faux points aberrants dans un jeu de données sans points aberrants (voir la figure 1 ci-dessous); ou dans le cas de véritables valeurs aberrantes, cela ne réduit pas suffisamment la valeur, ce qui la maintient à un niveau bien supérieur à nos attentes. C’est une approche qui finit par nécessiter une analyse critique très précise de la part du planificateur/prévisionniste; elle n’est donc pas aussi efficace et fiable qu’elle le devrait, car elle supprime les valeurs hautes et basses d’un jeu de données, même si elles ne sont pas exceptionnelles en soi.
Détecter les valeurs aberrantes via la méthode de l’écart type
Une autre approche consisterait à utiliser la variation de la demande autour de la moyenne historique et à exclure les valeurs exceptionnellement éloignées de cette moyenne, selon un certain intervalle compris entre deux seuils centrés sur la demande .
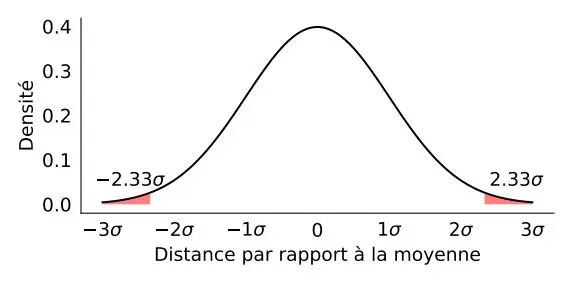
Avec cette méthode, dans une situation sans valeur aberrante, nous ne modifions aucune observation de la demande (nous conservons toutes les valeurs dans ce cas), et dans une autre situation avec une valeur aberrante (voir Y2 ci-dessous), nous ne modifions pas les points de demande faible ou élevée. mais seulement la valeur aberrante réelle (de 100 à 49 dans la figure ci-dessous).
Détecter les valeurs aberrantes via l’erreur de l’écart type
Pour résoudre les inconvénients de l’écart type et de la Winsorization, revenons à la définition d’une valeur aberrante. Une valeur aberrante est une valeur à laquelle vous ne vous attendiez pas. En d’autres termes, il s’agit d’une valeur éloignée de votre prédiction (c’est à dire votre prévision). Pour repérer les valeurs aberrantes, nous devons donc analyser l’erreur de prévision et voir quelles périodes sont exceptionnellement fausses. Si nous calculons l’erreur de notre prévision, nous obtiendrons une erreur moyenne et un écart-type. Vous pouvez consulter le livre Data Science for Supply Chain Forecast, écrit par Nicolas Vandeput pour voir des exemples de la vie réelle et plus de détails. La figure ci-dessous illustre nos résultats obtenus à partir de nos prévisions.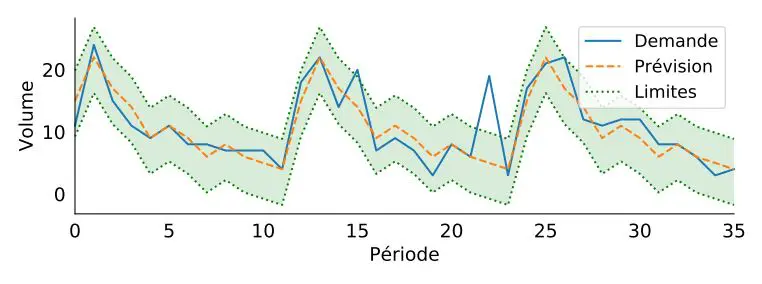
Cette méthode de détection plus intelligente, qui analyse l’écart d’erreur de prévision au lieu de simplement la variation de la demande autour de la moyenne, permet de signaler les points aberrants beaucoup plus précisément et de les ramener à une valeur plausible. Par conséquent, cela devrait être votre méthode préférée pour une prévision précise de la demande.
Essayez notre solution de prévision simple et rapide !
Inscrivez-vous aujourd’hui gratuitement sur SKU Science
Données d’échantillon rechargées – Aucune carte de crédit requise





